

連載企画第4回 統計を活用した意思決定の手法について
「統計を活用した意思決定の手法」として、前回は多重共線性(Multi-Co-Linearity:マルチ・コ・リニアリティ 通称:マルチコ)のチェック方法についてご紹介しました。これまで単回帰分析、重回帰分析、多重共線性への注意、といった分析手法の解説をしてまいりましたが、実務においてデータ分析をする場合、こうした手法以前に気を付けないといけないポイントがいくつかあります。今回はそのポイントやヒントについてご紹介します。
前回の連載までは、神奈川県における各市の住宅の平均価格を説明する要素について探った結果、住民の課税所得と幼稚園学級数で、住宅の平均価格がある程度説明できるということが分かりました。実務では、例えば「どの広告媒体を使えば、この商品の売上が最大化するのか調べて欲しい」という課題が上司から与えられることもあるかもしれません。皆さんが仮にこのような課題が与えられたら、まずどのようにアプローチするでしょうか。じつは実務上では、データ分析に入る前のプロセスが非常に重要なのです。
上司から「どの広告媒体を使えば、この商品の売上が最大化するのか調べて欲しい」という課題を与えられたと仮定すると、この上司の真意はどこにあるのでしょうか。仮にこの上司が宣伝部長で、新発売の商品を宣伝するにあたり、どの広告媒体に資金を振り分けるのかを考えているのであれば、「この広告媒体に投資するのが最もリーズナブル」と回答するのが、上司のニーズに沿った対応になるでしょう。
しかしこの上司がマーケティング部長だったらどうでしょうか。有限である資金を広告に配分するのか、パッケージングに配分するのか、他のプロモーション手段に配分するのか、実はもっと幅広い視点からの回答が聞きたいのかもしれません。またもしその上司が社長だったら、マーケティングに資金を振り向けるべきなのか、サプライチェーンの構築に資金を振り向けるべきなのか、工場のオペレーション改善・生産性向上に資金を振り向けるべきなのか、そのような視点からの回答が聞きたいかもしれません。つまり、上司の立場によりニーズが異なるため、導き出す課題への回答方法も違ってくるのです。
したがって、最初に行うべきことは「誰が、何のために、何を知りたいのか」というニーズを的確に把握することです。次にそのニーズを満たすためのフレームワーク、つまりニーズを満たすための要因・評価軸を決めます。そして最後にその評価軸に沿って評価するにあたり必要なデータは何かを決めていくというプロセスを踏むことが必要になります。
そして、ここまでのプロセスを上司と確認し、文書の形で残しておくことが重要です。俗に言う上司と「ニギる」ということですが、これをきちんと文書の形で確認しておくことによって、上司からのちゃぶ台返しによる手戻りや、作業の途中で何をしたらよいのか分からなくて迷子になってしまう、というような状況を回避することができます。
この作業は言葉で言うのは簡単ですが、実務的には相当骨の折れる作業です。現実問題として、上司も最初の段階では、何が知りたいのか、ぼんやりとしかつかめていないこともあります。その段階で上司と合意して進めたとしても、分析が進むにつれ、上司のニーズがだんだんとはっきりしてきて、その分析の方向性が変更されてしまうこともあるかもしれません。そんな時は「まじっすか・・・」と言いつつ天を仰ぎ、遠い目をせざるを得なくなるかもしれませんが、仕方ありません。
そんな場合でも、きちんと最初の段階で文書の形で残しておくことにより、「当初の方針はこうだったが、こういう変更をした」というプロセス・目的変更について、上司にも認識してもらうことができます。このプロセスを踏まないと、「あいつはいつもピントのずれた分析をするから、俺が直してやった」というふうに、上司の記憶が都合よく書き換えられてしまい、自分の評価が下がるという、サラリーマンとしては極めて恐ろしい結果になりかねません。くれぐれも気を付けましょう。
さて、次に注意すべき点です。データを入手することが出来たとしても、いきなりExcelを立ち上げて分析してはいけません。データにはノイズと言われる「欠損値」や「外れ値」があります。これらをきれいに整理してからでないと、正しい分析ができません。次に、そのやり方について見ていきましょう。
可視化して全体感をつかむ
データ分析をする時にまずは全体感をつかむ必要があります。下のグラフはどちらも平均値12、標準偏差6.33です。数値だけで見るとまったく同じですが、見た目はまったく違いますよね。数字だけを見ると、データの傾向はまったく違うのに、同じ分布だと勘違いしてしまいます。そうなると分析の方向も異なりますし、当然出てくる結論も異なってきます。まずはヒストグラムや散布図等を作って、データを可視化し、全体感を確認しましょう。
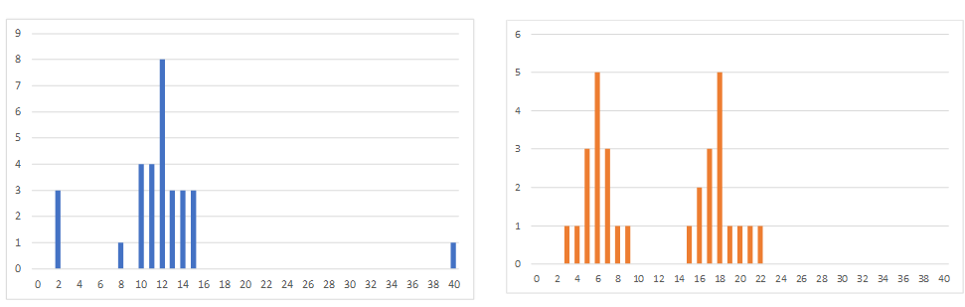
欠損値を探す
データセットを入手したとしても、すべてのデータが揃っているとは限りません。データの一部が欠けているかもしれません。これを「欠損値」と言いますが、これらのデータをそのままに放っておいたままでは適切な分析できない可能性があります。
例えばデータセットがExcelの形で入手できたとして、データセットによっては、欠損値がまったくの空白になっている場合もありますし、空白(スペース)が入力されているケースや、「-」が入力されているケースもあります。これらの欠損値はきれいにしてあげる(データクレンジングといいますが、これは後述します)必要があります。データの数が少なければ、これらの欠損値を目視で確認できるかもしれませんが、データの数が多ければ手作業で探し出すのは大変です。それぞれのデータセットによって、欠損値に何が入力されているか確認した上で、Excelの関数を使って、欠損値を特定しましょう。
もし欠損値に何も入力されていなければ、
=if([セルの位置]=””,1,””)
もし欠損値に数値以外の文字(スペースや「-」が入力されていれば、
=if(isnumber([セルの位置]),””,1)
といった関数を使うと、欠損値がある場合は「1」が出力されますので、Excelのフィルター機能を使って欠損値を特定することが出来ます。
外れ値を探す
外れ値とは、データセットの中で、他のデータに比べて大きすぎたり、小さすぎたりするデータです。大きすぎたり、小さすぎたりする値が混じっていると、平均や分散がそれらの数値に引っ張られて、正しい姿が見えにくくなる可能性があります。データセットの中に外れ値が混ざる原因は、データ取得時のミスや、偶然(非常に低い確率で)得られたデータといった理由が考えられますが、何らかの有意義な理由によって、その数値が出力されたという可能性もあります。
こうした外れ値を検出するためには、やはりデータを可視化することが大切です。先程使用したグラフを見てみましょう。
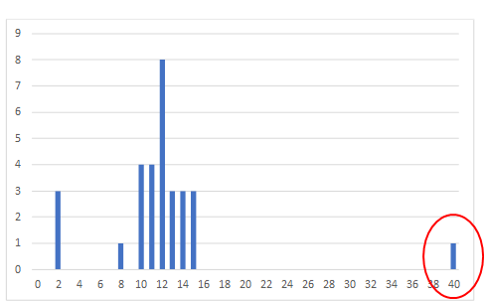
このデータセットは平均12、標準偏差が6.33というのは前述の通りですが、こうしてグラフの形で見てみると、40という数値を出しているデータが一つあります。これは平均12から大きく外れていますね。このデータが間違いなのか、何らかの意味があるのか、それを判断するのはこのデータだけから読み取るのは非常に難しいですが、データソースにあたってみると意外な発見があるかもしれません。
データクレンジング
データセットの分析を行う前に、上述の欠損値や外れ値について、修正もしくは除外することによって、データセットをきれいに整理する必要があります。これをデータクレンジングと言います。単純に除外して良いかどうかは、ケースバイケースなのですが(外れ値に大きな意味がある場合もあるため)、概ね以下のような手順で行います。
① データソースにあたって、なぜそのような値が出ているか確認する。
② データソースにあたっても理由が分からない場合、その数値は除外する。
しかし、もし除外したらデータの数が少なくなりすぎる場合は、平均値で埋める(その場合は、必ず分析に注釈を入れる)。
おわりに
データ分析から意味のある結論を導き出し、組織として成果を上げようとする場合は、すぐにデータ分析に着手するのではなく、まずは上司とのニギリ、そしてデータクレンジングといった前処理を丁寧にする必要があります。料理と一緒で、このような丁寧な仕込みをすることによって、出来上がりのプロダクトの質が大きく変わってきます。実務ではぜひ気を付けていただければと思います。
さてこれまで4回にわたり、統計を活用した意思決定の手法について紹介してまいりましたが、この記事が、皆さまの実務における業務品質向上の一助となれば望外の喜びです。最後までお付き合いいただきましてありがとうございました。
【参考文献】
はじめての統計学 鳥居泰彦(日本経済新聞社)
ビジネス統計学 上・下 アミール・D・アクゼル他(ダイヤモンド社)
文系のための理系的問題解決 多田実(オーム社)
Excelで学ぶ経営科学 多田実・大西正和他(オーム社)
本物のデータ分析力が身に付く本(日経BP)
【鷹野 慎太朗】














この記事へのコメントはありません。